 Thomas Heinrichs
Thomas Heinrichs 
Am 29. April durften Dominik und ich am Weizenbaum-Institut in Berlin einen Vortrag halten. Geplant war er unter dem Titel “Deterministische und Agentic Workflows. Wie wähle ich die richtige Variante?”. Drei Monate nach der Planung des Vortrags war diese Frage in unseren Köpfen längst nicht mehr die spannendste, denn die AI-Welt war weitergezogen.
Was uns in den Wochen davor eigentlich beschäftigt hatte, war eine andere Frage: Wie machen wir AI für die Prozessautomatisierung wirklich zugänglich? Nicht nur, indem wir AI aus Prozessen heraus nutzen, sondern auch andersherum gedacht: Wie kommen unsere Prozesse in die AI? Genau diese Perspektive haben wir in Berlin auf die Bühne gebracht. Für alle, die nicht dabei sein konnten oder noch tiefer einsteigen wollen, ist dieser Blogbeitrag genau das Richtige.
Die Frage hat sich verschoben
Als wir den Talk eingereicht haben, war Agentic Orchestration ein heißes Eisen. Hersteller wie Camunda und ServiceNow hatten gerade angekündigt, AI-Agenten in ihre Engines einzubetten, ohne den deterministischen Prozess zu beeinträchtigen. Der Prozess dient dabei als Leitplanke für die Agenten, sodass sie sich z. B. selbständig in einem Ad-hoc-Subprozess bewegen können. Drei Monate später ist genau das ein akzeptiertes Mittel der Wahl, und die alte Diskussion damit weitgehend abgeräumt. Klar sollte trotzdem immer hinterfragt werden, ob ein Agent wirklich notwendig ist oder ob sich das Problem nicht deterministisch und mit weniger Overhead lösen lässt.
Aber diese Diskussion wollten wir nicht noch einmal aufwärmen, vor allem weil wir das größere Potential woanders sehen. Stattdessen interessierte uns eine Frage, die deutlich weniger beantwortet ist:
Was passiert mit unserem Tooling, wenn die AI nicht mehr in den Prozess eingebettet wird, sondern der Prozess in die AI?
Das klingt nach einer rhetorischen Spielerei, ist es aber nicht. Um zu verstehen, warum das so ist, lohnt sich ein kurzer Blick in die Geschichte des Internets, denn AI macht gerade exakt dieselbe Bewegung durch.
Vom “AI im Tool” zum “Tool in der AI”
Phase 1: Pro Online-Dienst eine eigene Software
Wer in den späten 90ern online war, hat das Internet nicht über einen offenen Browser betreten, sondern über die Software seines Anbieters. T-Online lieferte ein eigenes StartCenter aus, AOL den AOL-Client. Das Internet kam gewissermaßen huckepack mit dem Tool, das man installiert hatte. Wer wechselte, wechselte die ganze Welt.

Phase 2: Der Browser als Universalwerkzeug
Mit Netscape und später dem Internet Explorer entstand eine neutrale Laufzeit für alle Inhalte. Der Browser kannte das eigentliche Ziel nicht, sondern stellte nur dar, was eine beliebige Website lieferte. Anbieter mussten ihr Internet nicht mehr mitliefern. Sie integrierten ihre Inhalte in das Internet, das es jetzt unabhängig von ihnen gab.
Phase 3: Fast jede Anwendung ist eine Webanwendung
Spotify, Slack, Notion, Figma, Teams. Selbst was wie eine native Desktop-App aussieht, ist im Kern eine Webanwendung. Die Frage, ob ein Anbieter sein eigenes Browser-Frontend ausliefert, stellt sich gar nicht mehr. Browsertechnologie ist Commodity.
Der Link zur AI
Genau dieses Muster sehen wir gerade mit AI, nur deutlich schneller. Die ersten Versuche bestanden darin, AI in das eigene Produkt zu integrieren. Camunda baute “Generate with AI”-Buttons in den Web Modeler, jedes SaaS-Tool bekam einen Chat-Assistenten unten rechts. Inzwischen zeichnet sich aber eine Gegenbewegung ab. Noch ist sie ein Rand-Phänomen, gewinnt aber spürbar an Traction und wird absehbar Fahrt aufnehmen: Erste Hersteller integrieren nicht mehr AI in ihr Produkt, sondern ihr Produkt in den AI-Client. Der Client, in dem ohnehin schon gearbeitet wird, wird damit zum neuen Interface.
Salesforce hat im April beispielsweise mit Headless 360 das erste CRM angekündigt, das nur noch über API, MCP und CLI zugänglich ist, ohne mitgelieferte Oberfläche. “Why should you ever log into Salesforce again?” fragt Co-Founder Parker Harris. Nicht als Provokation, sondern als Richtungsentscheidung.
Wenn diese Vision aufgeht, gilt sie genauso für Process Engines und die Tools drumherum: Cockpit, Tasklist, Monitoring und Reporting.
Das Problem mit dem klassischen Tooling
Schauen wir uns den Status quo der Prozessautomatisierung an. Im Zentrum steht die Engine. Drumherum: Cockpit für Operations, Tasklist für die Abarbeitung von User-Tasks, Dashboards fürs Management, Monitoring für Development und Ops. Vier Rollen, vier Oberflächen, vier Lernkurven. Sobald etwas nicht nach Plan läuft, springen alle Beteiligten zwischen den Tools, um sich Kontext zusammenzusuchen. Daten der Umsysteme wie CRM, Fachsystem oder Identitätsmanagement fehlen ohnehin und müssen zusätzlich noch reingeholt werden. Die Engine ist, was Daten und Co. angeht, quasi isoliert. Sie orchestriert zwar, aber für den gesamten Überblick reicht das nicht.
Das ist auch ein wesentlicher Grund, warum der BPM-Lifecycle in vielen Organisationen nicht wirklich gelebt wird. Iterative Optimierung scheitert oft schlicht an der Datenfragmentierung und an der Reibung im Tooling. Schnell reicht z. B. Camunda Optimize allein nicht mehr aus, sondern es braucht zusätzlich Tableau und Co., um die Daten der Process Engine mit denen aus anderen Fachsystemen zu kombinieren.
Unsere These, um genau diese Schmerzen zu lindern, ist daher: Den Prozess zur AI bringen. Wir verlagern die Interaktion mit dem Prozess dorthin, wo Wissensarbeit ohnehin schon stattfindet: in den AI-Client. Das Interface ist dann die Konversation selbst. Kein zusätzliches Feature in der Engine, sondern eine vollständige Interaktionsschicht über die Rollen hinweg.
Genau diese Schicht haben wir mit Miragon AI gebaut. Wie sie technisch funktioniert, schauen wir uns als nächstes an.
Die Technologie hinter der Interaktionsschicht
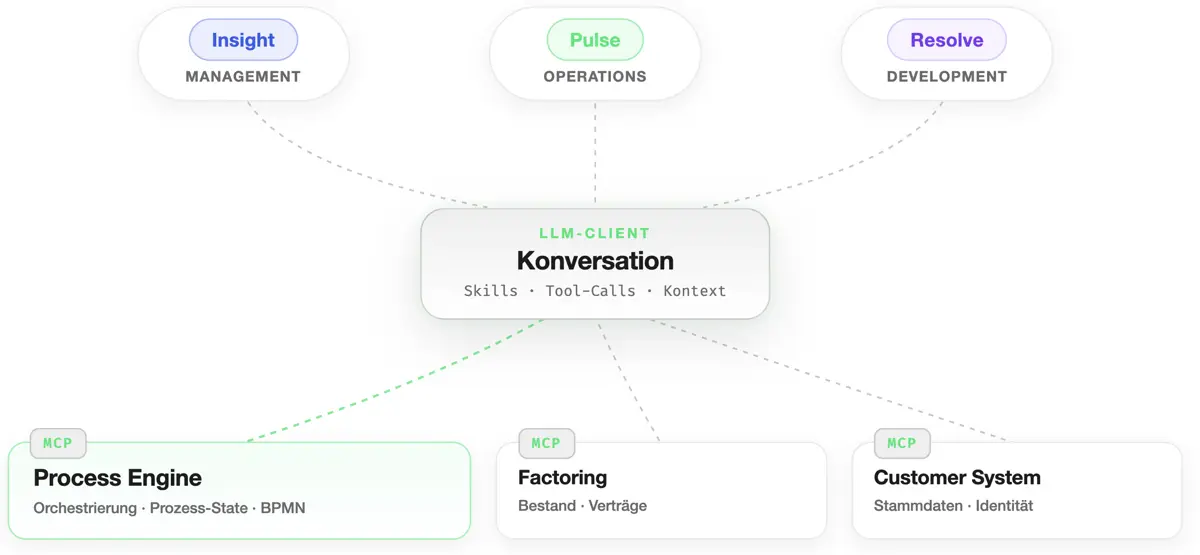
Die Architektur ist bewusst schlank. Im Zentrum steht ein beliebiger MCP-fähiger LLM-Client, also Claude, ChatGPT oder was im Team ohnehin schon im Einsatz ist. Über das Model Context Protocol (MCP) sprechen wir die Process Engine, Fachsysteme, Stammdaten und beliebige weitere Quellen an. Die Engine selbst bleibt unverändert.
Exkurs: Was ist MCP?
Das Model Context Protocol ist ein offener Standard, der von Anthropic initiiert wurde und mittlerweile von Claude, ChatGPT und vielen weiteren Clients unterstützt wird. Man kann es sich vorstellen wie USB-C für AI-Anwendungen: Statt für jede Integration einen eigenen Adapter zu bauen, sprechen Client und Datenquelle ein gemeinsames Protokoll.
Ein MCP-Server stellt einer LLM-Anwendung dabei drei Dinge bereit:
- Tools: ausführbare Funktionen, etwa “Incident lösen” oder “Prozessdefinition starten”.
- Resources: lesbare Daten wie XML-Modelle oder Stammdaten.
- Prompts: vorgefertigte Anweisungen für wiederkehrende Aufgaben.
Der Client entdeckt diese Fähigkeiten zur Laufzeit und stellt sie dem LLM zur Verfügung, ohne dass das anbindende System an einen bestimmten AI-Anbieter gebunden ist.
Mehrere Systeme in einem Chat zusammenführen
Diese Architektur eröffnet einen weiteren Hebel: Wir können beliebige Systeme anbinden. Mit Miragon AI haben wir ein Framework, um mehrere MCP-Server zu kombinieren. So greifen wir nicht nur auf die Daten einer Engine zu, sondern auch auf die anderer Systeme. Der AI-Agent kann diese Daten dann miteinander korrelieren.
Auf dieser Basis bieten wir drei rollenspezifische Profile an:
- Insight für das Management. Dashboards, Kennzahlen, Trends.
- Pulse für Operations. Live-Status, Incidents, Eskalationen.
- Resolve für Development und Modellierung. Diff, Refactoring, Debugging.
Die Profile sind im Wesentlichen kuratierte Prompt-Bündel mit Tool-Berechtigungen. Kein neuer Client, kein neues Frontend.
Wenn Text nicht reicht: MCP Apps
So weit, so MCP. Was MCP allein nicht löst: Wie zeige ich dem Nutzer eine UI, die mehr ist als Text? Ein Dashboard, eine Heatmap, ein Diff.
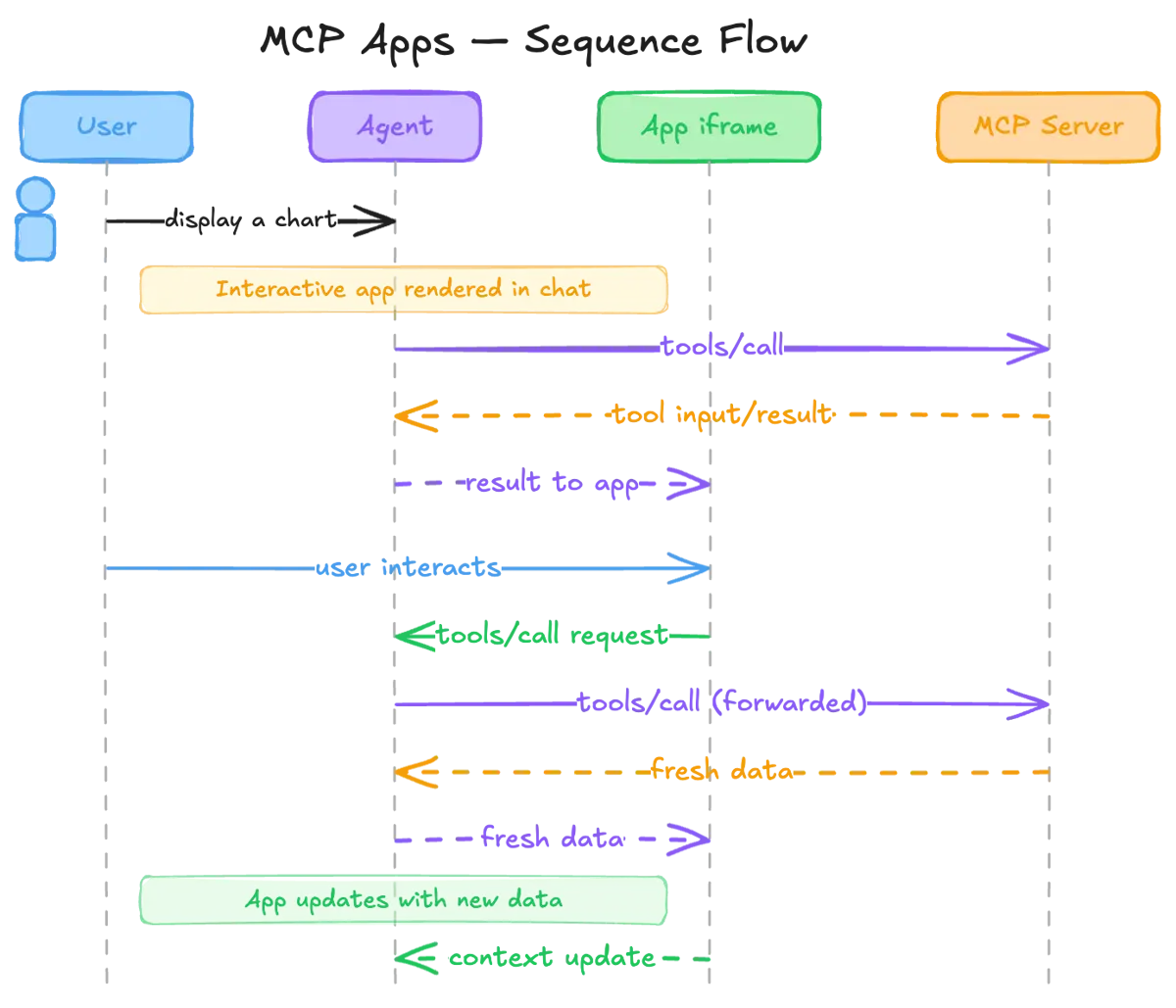
Genau diese Lücke schließt MCP Apps, ein neuer Standard, der die MCP-Spezifikation um interaktive UIs erweitert. Mit einem einzigen Tool-Call entsteht eine vollwertige, interaktive Oberfläche im Chat. Kein Aneinanderreihen von fünf Tool-Calls, kein wiederholtes Output-Auswerten. Genau das ist für Analyse-Use-Cases entscheidend, in denen Latenz alles ist.
Der Standard lebt im Repository modelcontextprotocol/ext-apps (daher die Kurzform “ext-apps”) und wird inzwischen von Claude, ChatGPT und weiteren Clients unterstützt. Technisch greifen vier Schritte ineinander:
- Tool-Definition. Ein MCP-Tool deklariert eine
ui://-Resource, in der eine HTML/JS-Oberfläche steckt. - Tool-Call. Das LLM ruft das Tool auf dem Server auf.
- Host rendert. Der Chat-Client holt sich die Resource und rendert sie in einer sandboxed iframe direkt in der Konversation.
- Bidirektionale Kommunikation. Der Host reicht Tool-Daten per Notification an die UI, die UI kann ihrerseits über den Host weitere Tools aufrufen.
Wie sich das in der Praxis anfühlt, zeigen wir am Beispiel eines fiktiven Kunden.
Szenario: Bike-Leasing bei MiraVelo
MiraVelo baut und vertreibt Fahrräder selbst und bietet sie zusätzlich als Leasing an. Wir betrachten den Leasing-Prozess: vom eingehenden Antrag bis zur Bewilligung oder Ablehnung.
Der Prozess startet mit dem Leasing-Antrag eines Kunden. Im besten Fall läuft er dunkelverarbeitet durch: Stammdaten werden aus dem CRM gezogen, der Bonitätscheck ist in Ordnung und die Police verschickt. Schlägt der Bonitätscheck fehl oder werden Risiken identifiziert, übernimmt ein menschlicher Sachbearbeiter die Entscheidung über Bewilligung oder Ablehnung. Bleibt eine solche Entscheidung länger als zwei Stunden liegen, wird der zuständige Manager benachrichtigt und kann nachsteuern.
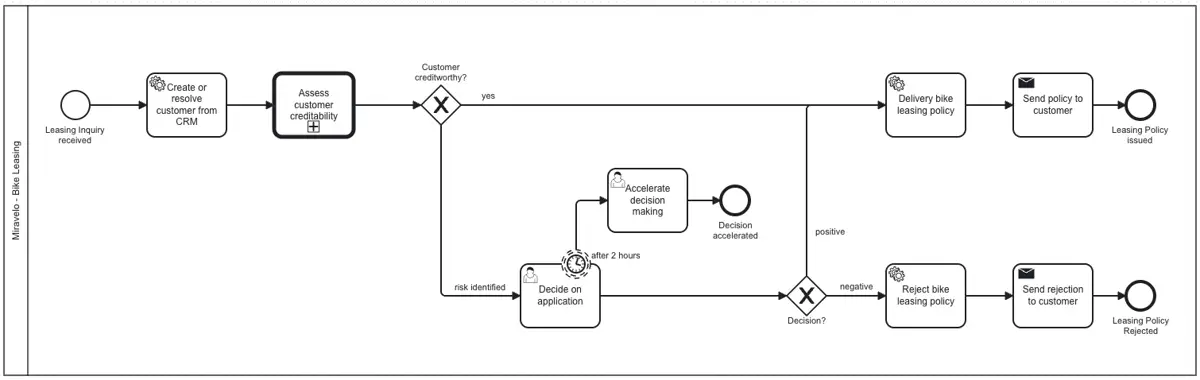
Wir haben hier also eine Mischung aus User Tasks, Service Tasks und einer Call Activity für die Bonitätsprüfung. Damit ist der Prozess repräsentativ für viele BPMN-Modelle, die wir in Kundenprojekten sehen.
Anhand dieses Beispiels wollen wir nun den BPM-Lifecycle mit Miragon AI durchlaufen und schauen, wo das Potential liegt.
Die Implementierungsphase überspringen wir bewusst. Dort gibt es bereits viel funktionierendes Tooling, und unsere Wette liegt auf den anderen drei Phasen.
Model: Live-Feedback im BPMN iQ Modeler
Bevor MiraVelo überhaupt mit der Modellierung startet, sitzen Fachbereich und Entwicklung in mehreren Collaborative-Modeling-Workshops zusammen. Dort werden Scope und Abgrenzungen festgelegt, Begriffe definiert und alle Stakeholder auf einen gemeinsamen Stand gebracht. Erst wenn dieses Fundament steht, läuft die anschließende Detailmodellierung auch in die richtige Richtung.
Auf dieser Basis übersetzt ein Entwickler den Prozess im BPMN iQ Modeler in eine erste ausführbare BPMN-Version und gibt per Klick auf Share einen Link an den Fachbereich weiter. Dieser kommentiert direkt im Diagramm, etwa an der Bonitätsprüfung, die als eigener Subprozess miravelo-creditworthiness modelliert ist. Während die Stakeholder kommentieren, arbeitet ein AI-Agent im Hintergrund die offenen To-Dos an der XML-Repräsentation ab: etwa eine vollständige Übersetzung des Prozesses ins Deutsche, eine Vereinheitlichung der Activity-Namen oder das Einsetzen passender Listener. Der Entwickler reviewt die Änderungen unter anderem mit Hilfe einer Diff-Ansicht. Der Fachanwender sieht im Gegenzug direkt, welche Auswirkungen seine Kommentare auf den Prozess haben.
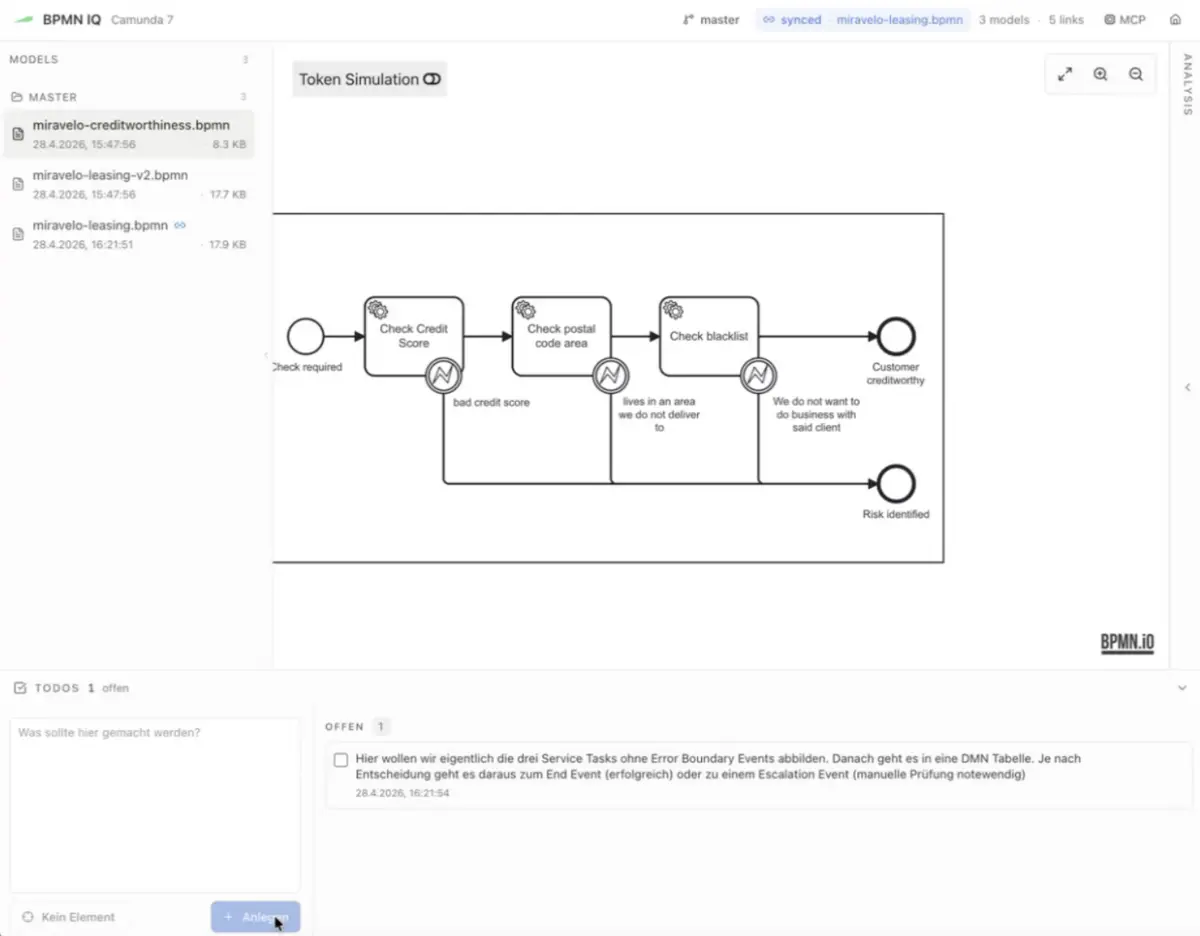
Das Feedback, das wir auf diese Weise im Modeler einarbeiten, betrifft nur noch Details, die sich ohne erneuten Workshop ergänzen lassen. Die Grundsatzentscheidungen sind vorher in den Workshops gefallen, und gerade durch den Einsatz von AI werden diese sogar wichtiger: Sie setzen das Fundament, auf dem die nachgelagerte AI-Arbeit überhaupt zielgerichtet bleibt.
Execute: Incident-Analyse direkt im Chat
Der Leasing-Prozess läuft inzwischen produktiv. Eines Morgens häufen sich plötzlich die Beschwerden: Kundenanträge bleiben offenbar irgendwo im Prozess hängen. Statt sich ins Cockpit einzuloggen und sich durch drei Reiter zur richtigen Definition zu klicken, genügt im Chat die Frage: “Zeig mir das Incident-Dashboard.” Die AI ruft den Analytics-Server auf, aggregiert Daten über Engine und Fachsysteme hinweg und liefert eine kompakte ext-app zurück:
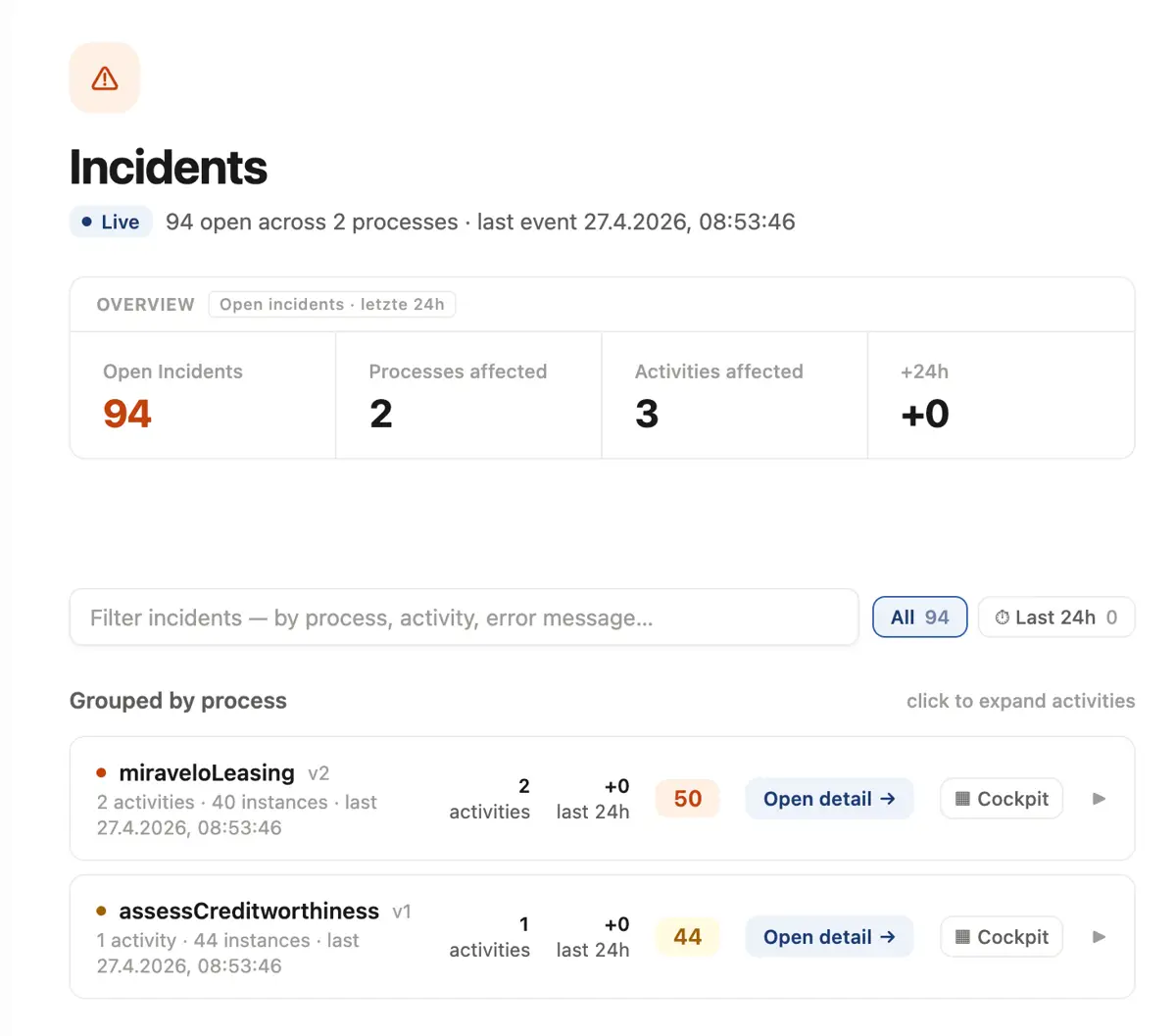
Aus dieser Übersicht lässt sich direkt in die betroffene Prozessdefinition oder in eine einzelne Instanz drillen. Lässt sich das Problem unmittelbar in der Engine beheben, kann der Operations-Verantwortliche den Incident aus derselben Oberfläche heraus auflösen. Stellt sich heraus, dass ein Eingriff durch die Entwicklung erforderlich ist, lässt sich per weiterem Tool-Call am angebundenen GitHub direkt ein Ticket mit den entsprechenden Informationen erstellen, ohne den Chat zu verlassen. Das erstellte Issue greift der Entwickler (bzw. dessen Coding-Agent) dann direkt auf und löst es.
Optimize: Dashboards, Heatmaps und Versionsvergleich
Operations kümmert sich jeden Tag um den stabilen Betrieb des Prozesses, aber die spannendere Frage kommt danach: Warum hängt der Leasing-Prozess regelmäßig an dieser Stelle? Welche Pfade laufen häufig, welche selten? Welche Modellversion war eigentlich besser? Genau hier setzen die analytischen Funktionen von Miragon AI an.
Dashboards im Dialog bauen
Der Stakeholder beschreibt im Chat, was er sehen will. Die AI generiert eine passende UI und rendert sie inline.
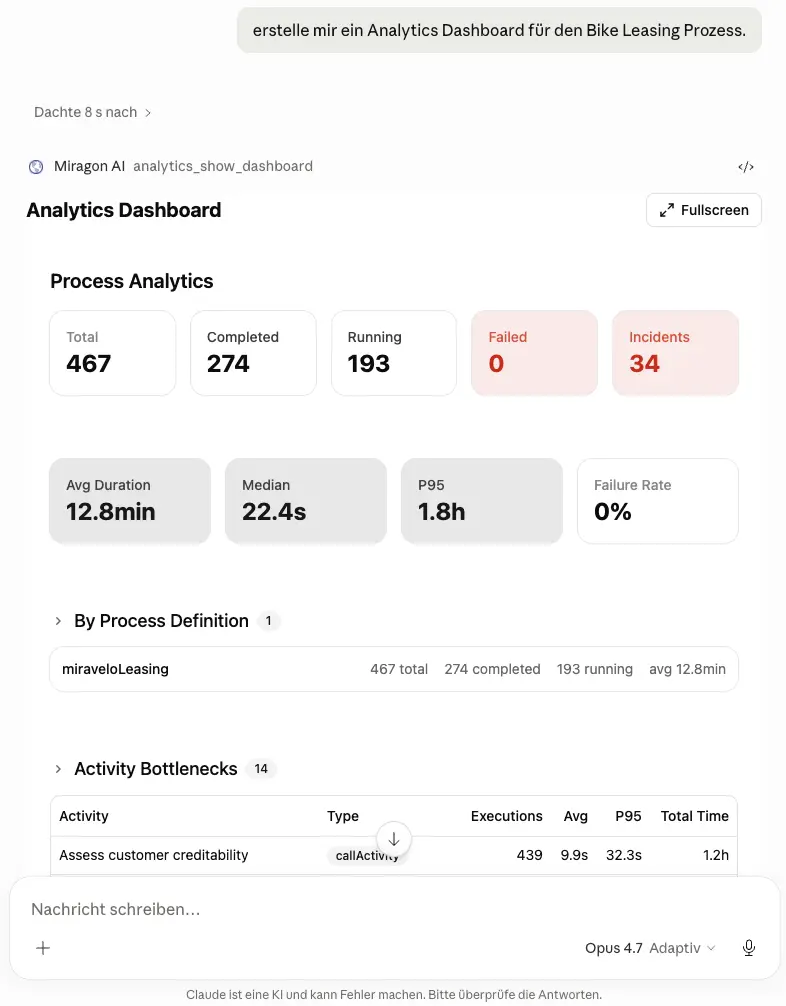
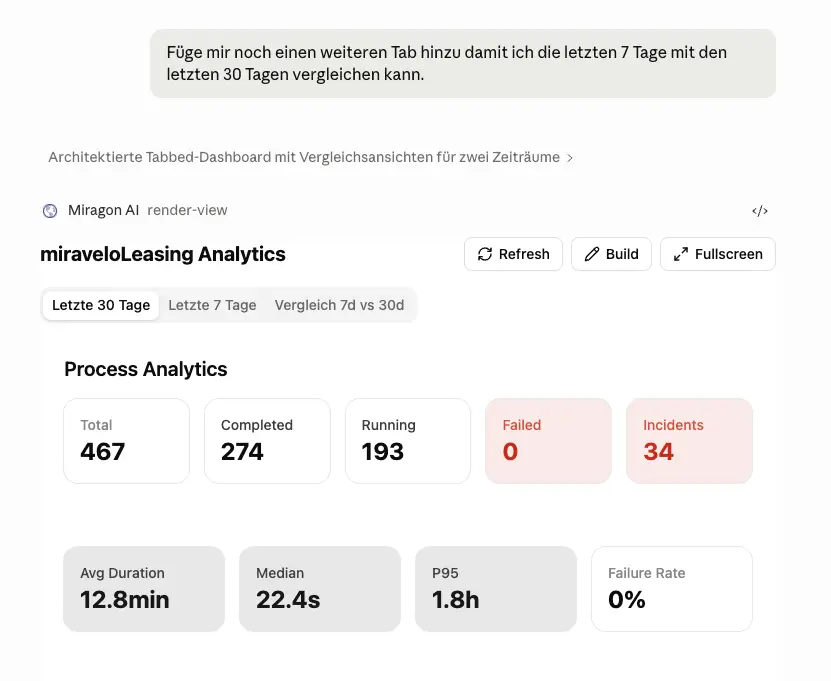
Iterieren funktioniert genauso direkt. Ein Folgeprompt wie “Füge mir noch einen weiteren Tab hinzu, damit ich die letzten 7 Tage mit den letzten 30 Tagen vergleichen kann.” erweitert die bestehende ext-app, ohne sie neu zu bauen.
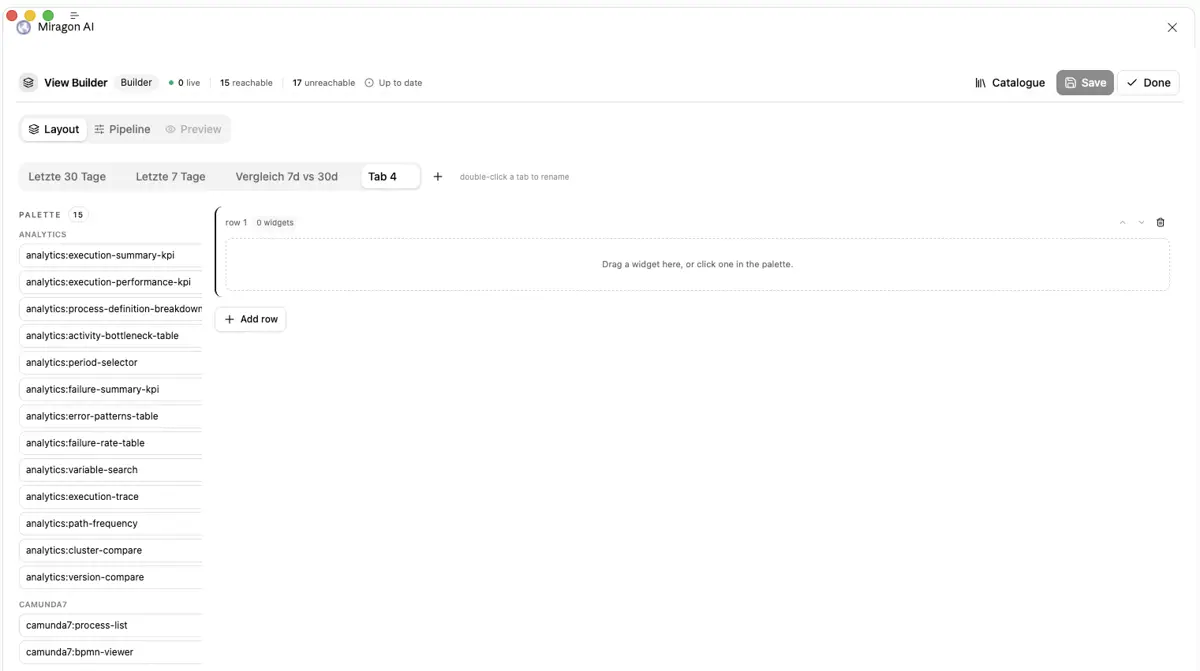
Reicht der Dialog im Chat für die Feinjustierung nicht, geht es per Build-Modus weiter. In einer Drag-and-Drop-Oberfläche mit Widget-Katalog lassen sich Tabs, Reihen und einzelne Widgets gezielt anordnen oder austauschen, immer auf derselben Daten-Pipeline, die auch die ext-app im Chat nutzt.
Der Unterschied zu einem klassischen Setup, in dem fünf Tool-Calls nacheinander aufgerufen und die Ergebnisse vom LLM zusammengetragen werden: Wir definieren in einer einzigen Pipeline, welche Daten wann aus welchem System extrahiert werden, um daraus die passenden Widgets zu befüllen. Das macht selbst komplexere Analysen interaktiv, schnell und nicht nur theoretisch agentic.
Aus der Analyse ein wiederverwendbares Werkzeug machen
Das eigentlich Spannende kommt danach: Das Dashboard lässt sich abspeichern. Beim Speichern wird eine ID vergeben, das gespeicherte JSON-Konstrukt landet im MCP-Backend. Will der Manager dieselbe Sicht später erneut öffnen, genügt eine kurze Chat-Nachricht mit dieser ID. Die Oberfläche wird dann mit frischen Daten direkt aus der Engine gerendert. So entsteht aus jeder einmaligen Analyse ein wiederverwendbares Werkzeug. Über Routinen in Claude lassen sich diese Reports zusätzlich automatisiert in regelmäßigen Abständen ausführen und zustellen.
Heatmaps und Pfadanalysen
Wo verbringen die Leasing-Instanzen die meiste Zeit? Welche Pfade durch das BPMN-Diagramm werden tatsächlich genutzt? Das schreit fast nach einer Heatmap. Auch die lässt sich als gerenderte UI direkt in den Chat zurückgeben.
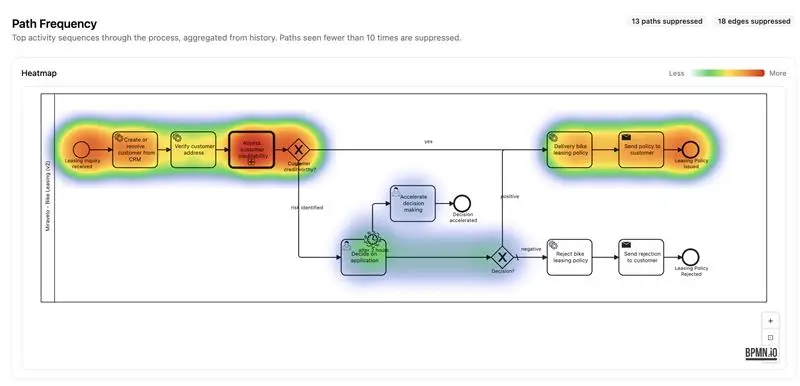
Die Heatmap legt die Pfadfrequenz auf das tatsächliche Diagramm. Modellnah, sofort interpretierbar, keine Übersetzung nötig.
Versionsvergleich von BPMN-Modellen
Eine Frage wie “Welche Prozessversion war die bessere?” führt zu einem tabellarischen Vergleich von Failure Rate, Incident Rate und Durchlaufzeiten, inklusive Hypothese, warum sich die Werte verändert haben. Im Beispiel: Eine restriktivere Bonitätsprüfung führt mehr Fälle in den manuellen Pfad und verlängert das 95. Perzentil deutlich.
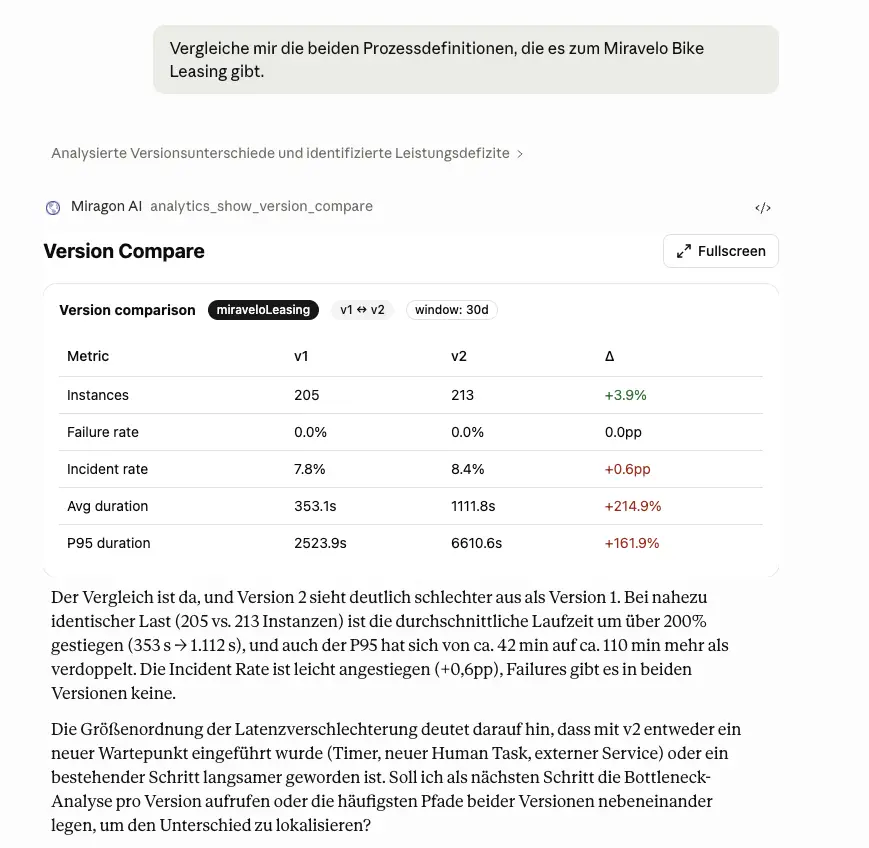
Auf Basis der Laufzeitdaten lassen sich darüber hinaus Optimierungsvorschläge durchsimulieren. Zum Beispiel: Was passiert, wenn ich eine weitere Bedingung an meinem Exclusive Gateway hinzufüge? Wie wirkt sich das auf die Durchlaufzeit aus? Werden die Mitarbeiter im Prozess dadurch entlastet?
Zurück in den Modell-Zyklus
Die gewonnenen Erkenntnisse aus der Optimize-Phase, etwa neue Bedingungen, geänderte Reihenfolgen oder ein zusätzlicher Pfad, landen wieder im BPMN iQ Modeler und damit am Anfang des Lifecycles. Aus der Analyse wird wieder ein Modell, der Loop schließt sich.
Bringt eure Prozesse in den Chat
Die Verschiebung des Interface ist aus unserer Sicht die deutlich größere Veränderung als ein AI-Agent im Prozess. Genau deshalb bauen wir bei Miragon unser AI-Tooling in diese Richtung auf. Wir wollen unseren Kunden nicht nur bei der Beratung und Umsetzung von Prozessen helfen, sondern sie auch befähigen, auf eine ganz neue Art und Weise mit Prozessen umzugehen, um noch mehr Potential aus diesen herauszuholen. Die vorgestellten Tools sind dabei nur der Anfang. Sie werden weiter ausgearbeitet und mit dem Feedback unserer ersten Kunden weiterentwickelt.
Das Ziel: Prozessautomatisierung dort verfügbar machen, wo ohnehin schon gearbeitet wird, also im AI-Client. Welcher Client das ist, entscheidet das Team. Alle gezeigten Screenshots stammen aus der Claude Desktop App, weil wir intern dort am häufigsten arbeiten. Da Miragon AI aber auf reinem MCP und MCP Apps aufsetzt, läuft dieselbe Funktionalität genauso in der Claude-Mobile-App auf dem Handy oder in einem anderen Frontier-Model-Client wie ChatGPT von OpenAI.
Mit ersten Kunden bringen wir Miragon AI bereits in die Praxis und etablieren diese Funktionalität in echten Automatisierungsumgebungen. Wenn euch das interessiert und ihr eure Prozesse in den Chat holen wollt, gibt es zwei Wege:
Schaut auf miragon.ai vorbei und tragt euch ein, wenn ihr auf dem Laufenden bleiben oder in einem Deep Dive mehr über das Tooling und die Einsatzmöglichkeiten erfahren wollt.
Oder einfach Hallo sagen, bei Dominik oder mir auf LinkedIn. Wir freuen uns auf den Austausch.


