 Thomas Heinrichs
Thomas Heinrichs 
Auf der CamundaCon 2026 in Amsterdam durfte ich gemeinsam mit Maria Alish, Product Manager & Business Analyst bei der IBA Group, einen Vortrag halten. Der Titel: „Beyond the Happy Path: Dealing with difficult Migrations”. Genau darum ging es uns: nicht um die glatte Demo-Migration, sondern um die Stellen, an denen es in echten Projekten knirscht.
Wir sehen in Projekten immer wieder dasselbe Muster: Eine Migration auf Camunda 8 wird als technisches Upgrade behandelt. Neue Engine, gleiche Prozesse, gleiche Business-Logik und dann ist man auch schon fertig. In der Realität ist das einer der teuersten Denkfehler, den man machen kann. Für alle, die nicht in Amsterdam dabei sein konnten, fassen wir hier die wichtigsten Erkenntnisse zusammen und stellen die vollständige Aufzeichnung des Vortrags zur Verfügung.
Die Aufzeichnung des Vortrags
Keine Migration, sondern eine Plattform-Transformation
Camunda 7 hat einen konsequenten Developer-First-Ansatz verfolgt. Die Engine ließ sich als Java-Bibliothek direkt in die eigene Anwendung einbetten, meist in einen Spring-Boot-Service, und lief damit in derselben JVM wie der restliche Code. Sie nutzte dieselbe Datenbank wie die Anwendung, nahm an derselben Transaktion teil, und je nach Bedarf standen verschiedene Deployment-Optionen vom embedded Betrieb über eine geteilte bis hin zur Remote-Engine zur Verfügung. Für ein Entwicklungsteam bedeutete das volle Kontrolle, eine durchgängig lokale Ausführung und ein Setup, das sich schlicht beherrschbar anfühlte. Camunda 8 verfolgt dagegen einen grundlegend anderen Anspruch: Es ist keine eingebettete Engine mehr, sondern eine Orchestrierungs-Plattform, die Menschen, Systeme, Geräte und zunehmend auch AI-Agenten miteinander verbindet.
Dieser Wechsel verändert nicht nur, wie du die Engine betreibst. Er verändert, wie deine Teams strukturiert sind und was Migration überhaupt bedeutet. Deshalb ist der Schritt zu Camunda 8 kein technisches Upgrade, sondern eine Plattform-Transformation. Wer das ignoriert, geht die Migration mit dem Camunda-7-Mindset an und wundert sich, dass Erwartung und Realität auseinanderlaufen.
Organizational Readiness: Camunda 8 ist nicht mehr dein Tomcat
Der erste und oft unterschätzte Block ist die organisatorische Bereitschaft überhaupt migrieren zu können. Viele Unternehmen, gerade im Corporate-Umfeld und in der DACH Region, verlassen sich noch auf klassische Application Server. Camunda 8 ist aber kein WAR auf einem Tomcat mehr:
- Kubernetes wird vorausgesetzt. Camunda 8 braucht eine echte Kubernetes-Umgebung mit PersistentVolumeClaims, mehreren Nodes und idealerweise einer Verteilung über mehrere Availability Zones.
- Netzwerk-Latenz wird plötzlich relevant. Zeebe repliziert seine Daten über das Raft-Protokoll zwischen den Brokern. Camunda empfiehlt deshalb, unter 50 ms Latenz zwischen den Broker- und Datastore-Nodes zu bleiben.
- Der sekundäre Datastore. Lange war Elasticsearch faktisch Pflicht. Wer dort die Index-Lifecycle-Policies vernachlässigt, sprengt schnell den Heap des Clusters, und ab diesem Punkt wird kein Event mehr exportiert. Die seit Kurzem verfügbare RDBMS-Unterstützung entschärft genau diesen Schmerz erheblich.
So weit die Theorie. Wie das in der Praxis kippt, zeigen drei Beispiele aus echten Projekten.
Banking: Wenn die Infrastruktur die Migration ins Stocken bringt
Eine Bank mit entkoppelter Camunda-7-Architektur wollte auf einen geteilten Camunda-8-Cluster wechseln. Schnell zeigte sich dabei das Noisy-Neighbour-Problem: Sobald die KYC-Domäne morgens 10.000 Prozesse gleichzeitig startet, leiden sämtliche anderen Domänen auf demselben Cluster mit. Die naheliegende Lösung, nämlich ein eigener Cluster pro Domäne, war schnell gefunden. Doch nach erheblichem zeitlichem Invest stellte sich heraus, dass das Infrastruktur-Team gar keinen Zugriff auf PersistentVolumeClaims hatte und auch keine passende Hardware bereitstand. Die Migration kam dadurch vollständig zum Stillstand. Nicht wegen der Engine, sondern wegen der Komplexität der Infrastruktur.
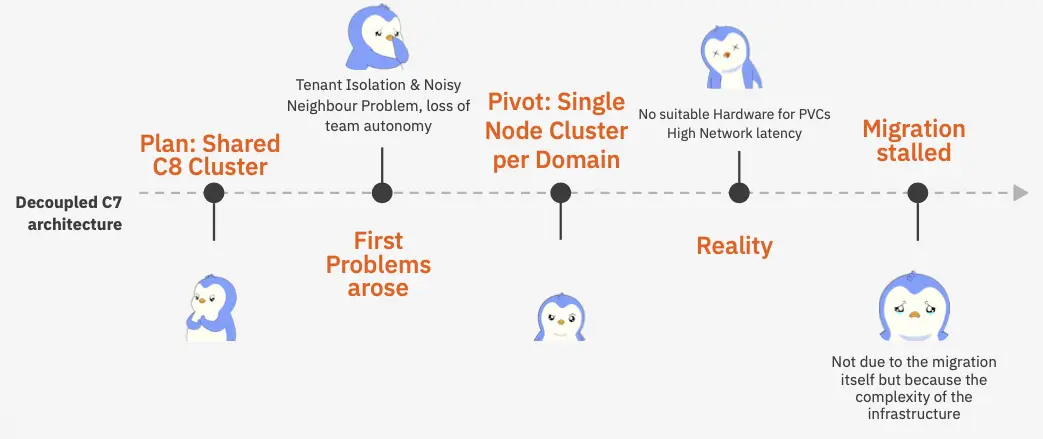
Retailer: Die Migration, die rückwärts ablief
Ein großer Retailer hatte die Anforderung, an jedem einzelnen Standort redundante On-Premise-Cluster zu betreiben, was in Summe auf rund 60 Camunda-8-Cluster hinauslief. Das Operations-Team ging daraufhin auf die Barrikaden und erklärte einen Betrieb in dieser Größenordnung schlicht für nicht leistbar. All dies resultierte in einer Migration zurück auf Camunda 7. Und auch hier lag der Grund nicht in einer schlechten Engine, sondern darin, dass die operative Realität nicht zu den organisatorischen Rahmenbedingungen passte.
Versicherung: Wenn JBoss auf Zeebe trifft
Eine Versicherung migrierte von einer Legacy-BPM-Engine, die ebenfalls als embedded Service eingebunden ist. Entwicklung und Betrieb waren dort strikt voneinander getrennt, und das Infrastruktur-Team kam aus der klassischen Application-Server-Welt rund um JBoss. Den Betrieb eines verteilten Zeebe-Clusters auf Kubernetes empfanden sie entsprechend als eine völlig neue Disziplin, und diese Lücke lässt sich nicht mit einem zweitägigen Training schließen. Das nötige Vertrauen entsteht erst über sogenannte Game Days, bei denen das Team Incidents gezielt simuliert und den Ernstfall so lange übt, bis der Betrieb wirklich sitzt.
Die Quintessenz dieses Blocks lautet: Choose SaaS if you can, self-manage if you must. Wer keine Site Reliability im Haus hat, fährt mit SaaS meist nicht nur einfacher, sondern auch wirtschaftlich besser. Die Total Cost of Ownership eines selbst betriebenen Camunda 8 ist dramatisch höher als beim alten Tomcat-Setup.
Team Topologies: Dein Dev-Team ist nicht dein Infra-Team
Wie im vorherigen Teil erläutert, bricht Camunda 8 das embedded-Engine Modell auf. Das hat auch Konsequenzen für das Teamsetup. In Camunda 7 lag die gesamte Verantwortung bei einem einzigen stream-aligned Team: Die Engine war Teil der Anwendung, also hat dasselbe Team sie deployt, betrieben und damit war die Sache erledigt. Mit Camunda 8 kommen dagegen Broker, Gateways, Exporter, eine eigene Datenbank, Monitoring, Backups und Disaster Recovery hinzu, und all das folgt einem anderen Skillset und einem eigenen Lebenszyklus. In Summe wächst die kognitive Last so stark, dass ein einzelnes Feature-Team sie nicht mehr stemmen kann.
Unsere Empfehlung für Teams, die von C7 nach C8 wechseln: nicht sofort ein Platform-Team aufsetzen. Startet stattdessen mit einem Complicated-Subsystem-Team aus Kubernetes- und Camunda-8-Experten, das eng mit den stream-aligned Teams zusammenarbeitet und über die nicht-funktionalen Anforderungen der Plattform diskutiert. Erst wenn das stabil läuft, lässt es sich zu einem Platform-Team weiterentwickeln, das Camunda 8 als internen Self-Service bereitstellt.
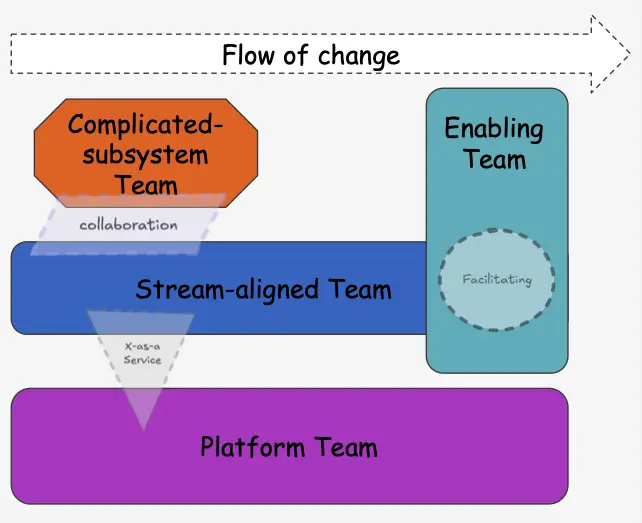
Diese Perspektive haben wir bereits ausführlich beleuchtet. Wer tiefer einsteigen will, findet sie in unserem Beitrag Camunda 7 vs. 8: Eine Betrachtung durch die Brille von Team Topologies.
Wo sollte man anfangen?
Mit Camunda 7 wirkten Prozesse oft angenehm strukturiert: klare Pfade mit klaren Übergängen, vergleichbar mit einem Fluss, über den nur ein paar wenige Brücken führen. Die tatsächliche Prozesslandschaft eines Unternehmens gleicht aber eher einer Stadt mit unzähligen, miteinander verbundenen Kanälen, in der zahlreiche Systeme über viele Abläufe hinweg voneinander abhängen. Was auf den ersten Blick einfach aussieht, ist es bei genauerem Hinsehen nur selten.
Daraus folgt der wichtigste strategische Grundsatz: Niemals migrieren um des Migrierens willen. Migriere, um Wert zu schaffen. Eine Migration, die nur das Bestehende auf einer neuen Engine nachbaut, hat keinen sichtbaren Business Outcome und ist damit das Erste, was gestrichen wird, sobald andere Prioritäten drängen.
Der bessere Ansatz: Beginne mit einem Prozess oder einer Domäne, die ohnehin modernisiert gehört, und nutze die Migration als Anlass für diese Verbesserung. Die erste Migration ist die erste Brücke in deinem neuen System. Bau sie an der richtigen Stelle, beweise das Muster an einem Lighthouse-Projekt, das sinnvoll, aber nicht geschäftskritisch ist, und der Rest wird zu Execution statt Innovation.
Key Decisions: Kein Big-Bang Dependency Swap
Bei den fundamentalen Entscheidungen, von Deployment bis Implementierung, ist die wichtigste: Tausche nicht einfach die Abhängigkeit aus und hoffe, dass alles läuft. Bewerte zuerst deine Prozesslandschaft. Manche Prozesse, die du vor fünf Jahren automatisiert hast, sind heute kein Wertbeitrag mehr, dafür gibt es inzwischen passende Standardprodukte. Ein hilfreiches Werkzeug für diese Bewertung ist Wardley Mapping: Es ordnet deine Prozesse entlang ihrer Evolution ein, von der individuellen Eigenentwicklung bis zur austauschbaren Commodity. So wird sichtbar, wo sich ein Standardprodukt lohnt und wo eine eigene Orchestrierung tatsächlich einen Wettbewerbsvorteil schafft.
Für die übrigen lohnt sich eine Abstraktionsschicht vor der Engine, ähnlich wie niemand mehr herstellerspezifisches SQL direkt schreibt. Genau dafür haben wir vor einiger Zeit die Process Engine API vorgestellt, die bei vielen Kunden produktiv im Einsatz ist und einen sauberen ersten Migrationsschritt ermöglicht.
Der Grund, warum ein Big-Bang Dependency Swap so gefährlich ist, ist die Consistency Trap, und sie trifft besonders diejenigen, die von embedded Camunda 7 kommen (remote/external Engines sind hier fein raus). In Camunda 7 lief alles in einer ACID-Transaktion: Service Task, Prozesszustand und DB-Write teilten dasselbe Schicksal. Schlug etwas fehl, rollte alles zurück. Camunda 8 arbeitet nach dem BASE-Modell: Das Abschließen eines Zeebe-Jobs und der Write in deine lokale DB sind zwei getrennte Systeme. Es gibt keine gemeinsame Transaktionsgrenze mehr: Partieller Erfolg wird möglich. Und das zeigt sich nicht unbedingt in Dev oder Test, sondern unter Last in Produktion.
Die daraus entstehenden Failure Modes sind real und keineswegs nur theoretisch: Zeebe arbeitet plötzlich auf Daten, die nach einem Datenbank-Rollback gar nicht mehr existieren, Worker lesen noch nicht committete Zwischenstände, und weil Zeebe nach dem Prinzip At-least-once zustellt, wird dieselbe Aktion gelegentlich doppelt ausgeführt. Eine universelle Lösung für all das gibt es nicht, der richtige Ansatz hängt immer von der konkreten Situation ab. Auf der Bühne haben wir deshalb ein mehrschichtiges Vorgehen gezeigt:
- Layer 1: Steuern, wann Zeebe aufgerufen wird. Ein After-Transaction-Hook ruft Zeebe erst als Callback auf, nachdem der Datenbank-Commit erfolgreich war. Wer ganz sicher gehen will, greift zum Outbox Pattern: Dabei werden die Geschäftsdaten und die Absicht, eine Nachricht zu senden, gemeinsam in einer einzigen ACID-Transaktion gespeichert, und ein separater Scheduler liest diese Nachrichten anschließend aus und stellt sie garantiert an Zeebe zu. Das erkauft man sich allerdings mit zusätzlicher Komplexität in der Codebasis.
- Layer 2: Duplikate sicher behandeln. Jeder Verarbeitungsschritt muss damit rechnen, dieselbe Nachricht mehrfach zu erhalten. Entweder sind die betroffenen Services von Natur aus idempotent, oder man führt ein Processed-Operations-Log, das festhält, welche Befehle bereits verarbeitet wurden, damit derselbe Befehl garantiert nicht zweimal ausgeführt wird.
- Layer 3: Nutzen, was die Engine selbst bietet. Zeebe kann eingehende Nachrichten über Message-IDs für eine begrenzte Zeit deduplizieren, und mit ausreichend feingranular modellierten Prozessen lassen sich Mechanismen wie Kompensation und das Saga-Pattern einsetzen, um fehlgeschlagene Teilschritte sauber zurückzurollen.
Wie tief dieses Thema geht, zeigt der ausführliche Deep Dive meines Kollegen Marco, der „30-Minuten-Read”, den wir auf der Bühne erwähnt haben: Leveling up! Wie du die Herausforderung verteilter Transaktionen in Zeebe lösen kannst.
Aus diesem Block nehmen wir drei Dinge mit.
- Erstens: Dein Entwicklungsteam ist nicht automatisch auch dein Infrastruktur-Team, denn beide Rollen verlangen ein unterschiedliches Skillset.
- Zweitens: Transaktionsgrenzen migrieren nicht von selbst, sondern müssen beim Wechsel auf Camunda 8 bewusst neu durchdacht werden.
- Und drittens: Binde dich nicht direkt an die API der Engine, sondern an eine Abstraktionsschicht, denn Camunda hat die APIs in den vergangenen Releases mehrfach verändert.
Die typischen Pitfalls
Migrationsprojekte scheitern nur selten allein an der Technologie, viel häufiger sind es falsche strategische Entscheidungen, die ein Projekt zu Fall bringen. Die folgenden Fallen begegnen uns dabei immer wieder:
- Kein Business Value. Solange eine Migration keinen messbaren Outcome liefert, verliert sie im Wettbewerb mit echten Geschäftsprioritäten schnell an Bedeutung und wird als Erstes zurückgestellt.
- Der Big-Bang. Der Versuch, alles auf einmal zu migrieren, erzeugt maximale Komplexität und maximales Risiko und nimmt dem Team gleichzeitig jede Möglichkeit, unterwegs zu lernen. So lässt sich nachhaltig keine Erfahrung aufbauen.
- Neues Spiel mit altem Mindset. Camunda ist längst nicht mehr nur eine eingebettete Engine, sondern entwickelt sich konsequent zur Orchestrierungs-Plattform. Wer das Produkt noch mit der Erwartungshaltung von Camunda 7 betrachtet, wird zwangsläufig enttäuscht, weil Anspruch und Realität nicht mehr zusammenpassen.
Ein Blick auf Camundas Roadmap
Für das Release 8.10 (Oktober 2026) zeichnen sich konkrete Bausteine ab: ein Unified Hub (Modeler + Console), Workspaces & Projects, ein Private Catalog für Wiederverwendung von Prozessbausteinen, AI-Enablement über MCP und Skills sowie automatisiertes Backup & Restore.
Aus Business-Sicht geht es dabei nicht um die einzelnen Features, sondern um drei Probleme, die jedes Unternehmen beim Skalieren von Automatisierung trifft: Coordination (wie mehrere Teams gemeinsam Prozesse bauen und betreiben), Governance (Konsistenz und Compliance) und Trust (Orchestrierung zuverlässig genug für produktive, geschäftskritische Workflows).
Wann migrieren? Es geht nicht um Timing, sondern um Readiness
Viele fragen uns: Sollen wir jetzt oder lieber später migrieren? Wir würden die Frage anders stellen: Sind wir im strategischen Fenster, in dem die Migration tatsächlich Business Value schafft?
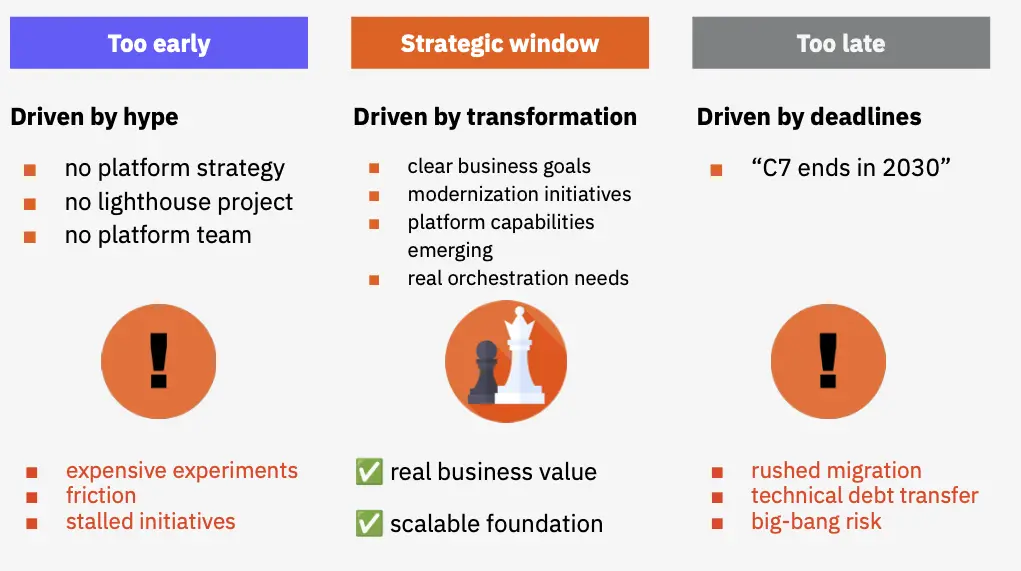
Wer zu früh startet, lässt sich vom Hype treiben: Es fehlt an einer Plattformstrategie, an einem Lighthouse-Projekt und an einem Platform-Team, und so experimentiert man zwar, kommt aber nie ins Skalieren. Wer zu spät startet, lässt sich von Deadlines treiben, überstürzt die Migration und schleppt dabei technische Schulden mit. Das strategische Fenster liegt genau dazwischen, nämlich dort, wo die Migration Teil einer größeren Transformation ist und auf eine vorhandene Cloud-Strategie, echte Orchestrierungs-Bedarfe und klare Geschäftsziele trifft. Erst dann hört die Migration auf, ein reiner Kostenfaktor zu sein, und beginnt tatsächlich, Wert zu schaffen.
Deshalb bedeutet „mit der Migration beginnen” zunächst nicht, Code zu schreiben, sondern Klarheit zu schaffen. Es geht darum, die eigenen Prozesse und die gesamte Systemlandschaft wirklich zu verstehen und zu erkennen, an welchen Stellen Orchestrierung überhaupt einen Unterschied macht. Letztlich entscheidest du damit, wie du die nächsten zehn Jahre Prozessautomatisierung betreiben willst. Bevor du startest, solltest du dir deshalb drei ehrliche Fragen stellen:
- Hast du einen klaren Grund für die Migration?
- Weißt du, wo du anfängst?
- Hast du die Fähigkeit, Camunda 8 in Produktion zu betreiben?
Bleibt eine dieser Antworten unklar, solltest du dir mehr Zeit für die Vorbereitung nehmen. Denn am Ende entscheidet die Readiness, nicht der Kalender.
Lass uns über deinen Fall sprechen
Wenn dich etwas davon abgeholt hat, freuen wir uns über den Austausch, egal ob du gerade vor der Entscheidung stehst oder schon mitten in einer Migration steckst.
Sag einfach Hallo, bei mir auf LinkedIn. Ich freue mich darauf, von deinem Projekt zu hören.
Und falls du den Vortrag noch einmal in Ruhe ansehen möchtest: Die vollständige Aufzeichnung von der CamundaCon 2026 findest du auf Vimeo.



