Wiederverwendbare Prozessbausteine
Wie wiederverwendbare Prozessbausteine in BPMN die Prozessmodellierung vereinfachen und Low-Code durch klare Schnittstellen ermöglichen.

Einleitung
Bei der Automatisierung von End-to-End-Prozessen müssen häufig verschiedene Anwendungen und Systeme integriert werden - nur wenig findet auf der grünen Wiese statt und hat keinerlei Schnittstellen. Doch selbst wenn dies der Fall ist, bieten Wiederverwendbarkeit und Low-Code einige Vorteile bei der Automatisierung von Prozessen - wie diese implementiert werden, ist jedoch entscheidend.
Wäre es nicht praktisch, wenn man verschiedene Funktionalitäten einfach und unkompliziert in unterschiedlichen Prozessen verwenden könnte? Das betrifft sowohl Basis-Funktionalitäten wie das Versenden einer E-Mail, das Erzeugen einer Rechnung oder das Speichern eines Dokuments, als auch prozessspezifische Aufgaben wie das Reservieren eines bestimmten Produktes in einem Warenlager - also nahezu alle Aktivitäten eines Prozesses.
Über die Verwendung von BPMN haben wir ein Low-Code-Tooling und eine Sprache an die Hand bekommen, um uns gemeinsam mit dem Fachbereich über den Ablauf eines Prozesses zu unterhalten. Außerdem haben wir Prozessexperten in die Lage versetzt, gemeinsam mit Entwicklern automatisierbare Workflows zu entwerfen.
Es mag sogar Anbieter von Zero-Code-Tools am Markt geben, die eine Automatisierung komplett ohne Entwickler versprechen. Um diese Art von Low-Code oder Wiederverwendbarkeit geht es in dieser Blogreihe aber nicht.
Für uns bedeutet Low-Code, dass Entwickler mit Standard-Technologien Funktionalitäten bereitstellen, die einfach wiederverwendet werden können.
Bei der Landeshauptstadt München haben wir im Projekt DigiWF, in dem vieler der hier vorgestellten Konzepte erarbeitet und angewendet wurden, genau dieses Vision-Statement definiert. Wir entwickeln unter Einsatz von offenen Standards Wiederverwendbarkeit für den Fachbereich.
Wiederverwendbare Prozessbausteine werden dabei von Entwicklern bereitgestellt und bei der Prozessmodellierung verwendet. Dadurch können Modelle einheitlicher gestaltet und die Modellierung vereinfacht werden. In einfachen Prozessen ist es uns sogar möglich, vollständig auf Entwickler zu verzichten. Low-Code durch Eigenentwicklung - in diesem Fall kein Widerspruch, sondern unser Vision-Statement.
In diesem ersten Blogpost der Reihe werden die grundlegenden Konzepte vorgestellt und aufgezeigt, welcher Nutzen für die Prozessmodellierung dadurch entstehen kann.
Anforderungen an die Wiederverwendbarkeit
Doch welche Eigenschaften müssen Schnittstellen und Aktivitäten erfüllen, damit sie in verschiedenen Prozessen wiederverwendet werden können?
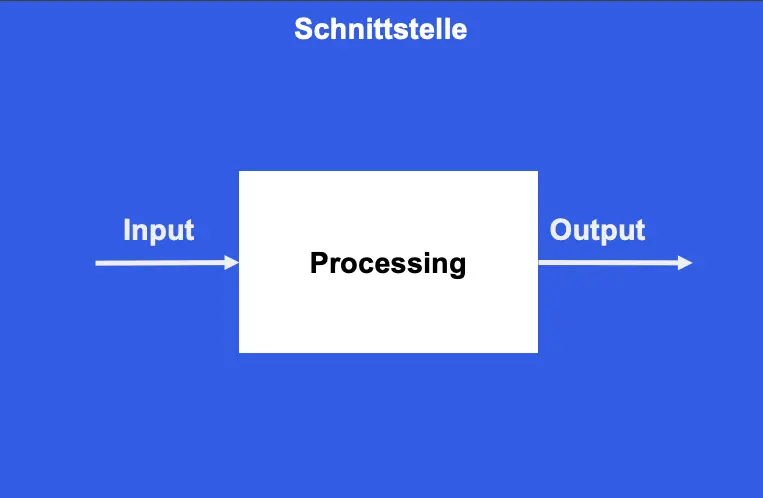
Eine Aktivität im Sinne der BPMN zeichnet sich dadurch aus, dass sie Daten für die Ausführung übergeben bekommt, Logik ausführt und Daten für die weiteren Schritte des Prozesses liefert.
Um Wiederverwendbarkeit bei einem Prozessbaustein zu ermöglichen, sollten zunächst die Schnittstellen definiert werden. Welche Daten werden für die Verarbeitung benötigt und welche Daten werden für die weitere Ausführung bereitgestellt?
Zugriff auf Daten
Bei der Automatisierung von Workflows kann in den entsprechenden Schnittstellen auf Daten zugegriffen werden, die sich in verschiedenen Kontexten befinden:
- Prozessinstanz
- Subprozess
- Aktivität
- …
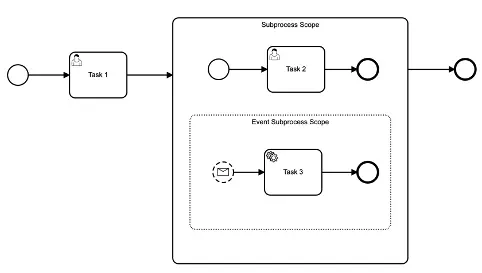
Ein Task hat stets auf die eigenen und die übergeordneten Daten Zugriff. Durch das Input- / Output-Mapping können einzelne Tasks in unterschiedlichen Kontexten wiederverwendet werden.
Wenn eine Aktivität in verschiedenen Prozessen wiederverwendet werden soll, sollte der Zugriff auf die Daten einheitlich erfolgen. Hier besteht die Möglichkeit, Daten prozessübergreifend unter dem gleichen Schlüssel zur Verfügung zu stellen oder ausschließlich auf die lokalen Daten der Aktivität zuzugreifen. Aus verschiedene Gründen bietet es sich an, ausschließlich auf lokale Variablen zuzugreifen:
- bessere und einfachere Wiederverwendbarkeit
- geringere Fehleranfälligkeit bei paralleler Verwendung
- klare Definition der Schnittstelle
- Versionierung der Schnittstelle
- Keine Überlappung verschiedener Schnittstellen
- Datenschutz und -sicherheit
- …
Schreiben von Daten
Das Gleiche gilt für das Bereitstellen von Daten. Entweder stellt die Schnittstelle lokale Daten bereit oder schreibt diese direkt in einen übergeordneten Scope der Aktivität. Auch hier sprechen die gleichen Argumente dafür, ausschließlich lokale Variablen zu schreiben und bei der Modellierung ein manuelles Mapping der bereitgestellten Daten zu definieren.
Vorteile
Zusammengefasst sollten die folgenden beiden Regeln eingehalten werden:
- Es wird ausschließlich auf lokale Variablen zugegriffen
- Es werden ausschließlich lokale Variablen geschrieben
Wenn wir uns daran halten, können wir uns langfristig eine Bibliothek an Schnittstellen aufbauen, deren Einsatzmöglichkeiten nicht auf einen einzelnen Prozess beschränkt sind.
Wiederverwendbarkeit anhand eines Beispiels
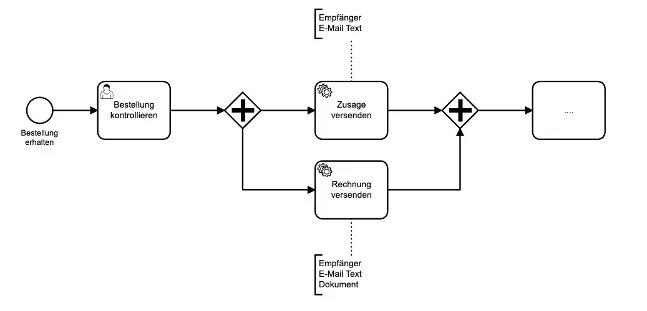
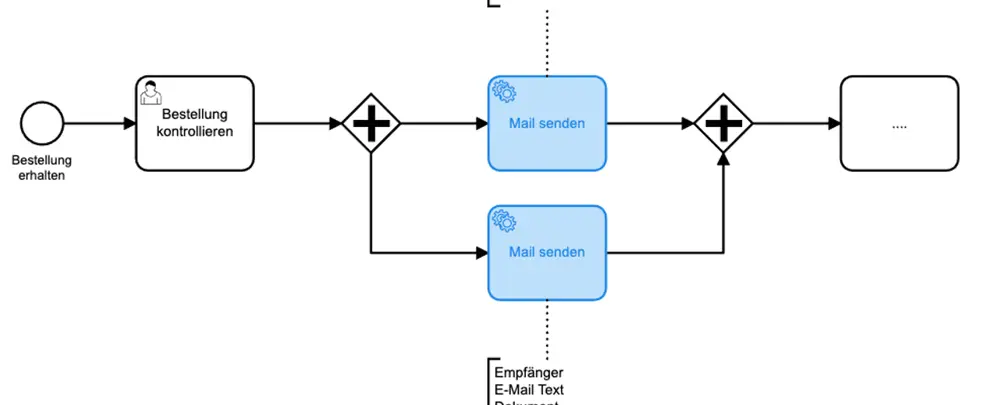
Im Prozess ist ein Ausschnitt eines vereinfachten Bestellprozesses zu sehen. Nachdem wir eine Bestellung erhalten haben, muss diese zunächst kontrolliert werden. Nach der Kontrolle wird die Bestellbestätigung und die Rechnung versendet. Bei genauere Betrachtung handelt es sich in beiden Fällen um dasselbe: den Versand einer E-Mail.
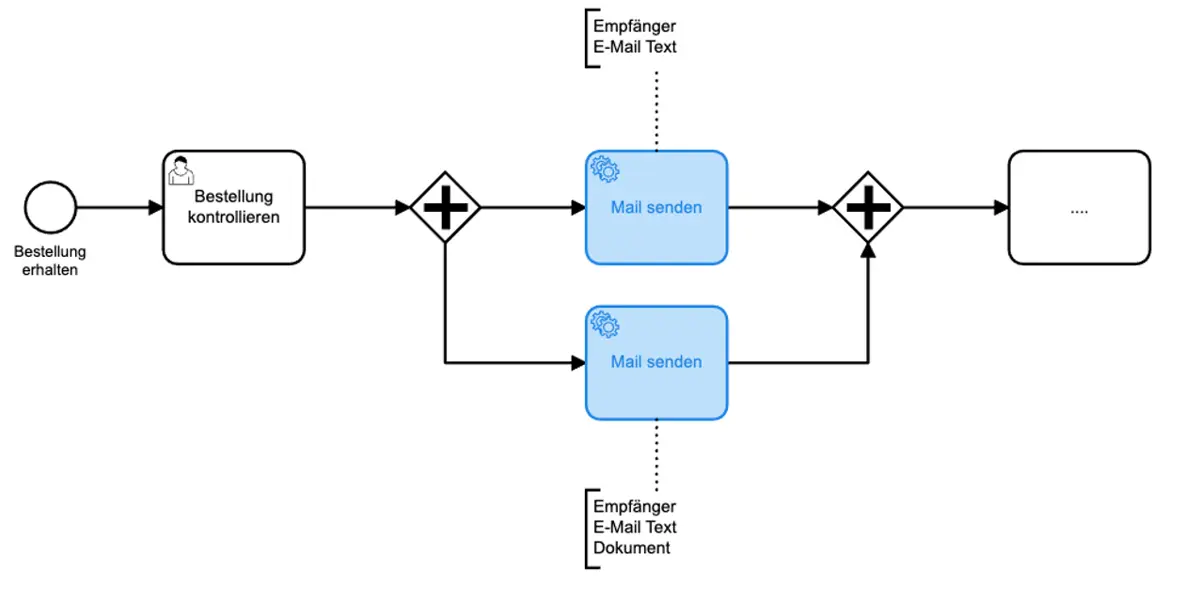
Die Funktionalität “E-Mail versenden” kann auf das Bereitstellen der Daten
- Empfänger
- Text
- Dokument
reduziert werden. Dadurch erhalten wir eine Funktion, die nicht nur im gleichen Prozessmodell, sondern auch prozessübergreifend wiederverwendet werden kann.
Ausblick
Doch wie können wir diese Schnittstellen bei der Modellierung verwenden, ohne das Mapping der Daten manuell vornehmen zu müssen? Im nächsten Blogpost lernen wir das Feature “Element-Templates” der Process Engine Camunda kennen und schauen uns an, wie wir durch Low-Code einfache Wiederverwendung ermöglichen und eine Bibliothek aufbauen können, die von unterschiedlichen Prozessen eingesetzt werden kann.

Fandest du den Artikel interessant?
Abonniere unseren Newsletter und erhalte neue Beiträge direkt ins Postfach.
Das könnte dich auch interessieren
Ähnliche Beiträge aus unseren Insights
Ausführbar, aber unlesbar: AI-bearbeitete BPMN-Modelle sauber halten
AI schreibt BPMN oft schon im ersten Versuch korrekt. Trotzdem kommt das Diagramm häufig kaputt heraus, denn sie sieht nie, was sie zeichnet. Dieser Post zeigt den Loop aus Erkennen, Beheben und Erzwingen, mit dem ich diese visuelle Lücke schließe. Und die Grenze, die ich dabei ziehe.


Beyond the Happy Path: Was eine Camunda-8-Migration wirklich schwer macht
Warum der Wechsel auf Camunda 8 kein technisches Upgrade ist, sondern eine Plattform-Transformation: Erkenntnisse aus unserem CamundaCon-2026-Vortrag in Amsterdam.

Warum wir uns gegen Microservices und für einen modularen Monolithen mit Camunda 7 entschieden haben
Warum ein modularer Monolith mit Camunda 7 für ein kleines Projektteam die bessere Wahl war und welche Trade-offs diese Architektur mit sich bringt.

Innerhalb eines Tages weißt du, wo du stehst.
Kein Verkaufsgespräch, sondern eine ehrliche Einschätzung, ob und wie Automatisierung dir hilft.
Erstgespräch vereinbarenKein Commitment. Kein Pitch-Deck. Nur Klarheit.